There's a new version of Oracle Application Express (APEX) in town, and one of the new "features" is a new region type called "Dynamic Content" that allows you to output content using PL/SQL.

What happened to the existing "PL/SQL Dynamic Content" region type that does exactly this, you might ask? It's still there, but now it's marked as "Legacy" and requires an extra mouse click just to be able to select it, and to make you feel bad for using it.
So why a new region type to replace the old one? The stated reason is to allow the region to be refreshed, but as readers of my blog will know, there are already ways of doing that, as demonstrated in this region plugin that I released in 2012.
In order to make the region refreshable, the APEX team had to change the way you use it. You no longer call the "HTP" package to add your content to a global output buffer. Instead, you have to concatenate and return your content as a string (varchar2 or clob). The way it's suggested in the online help is like this:
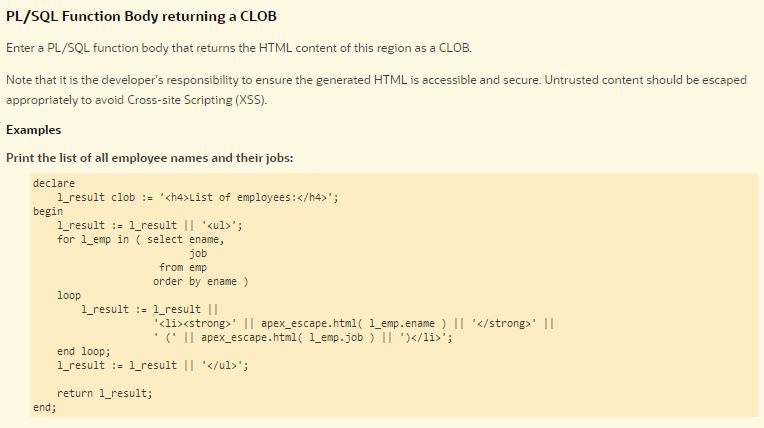
There are several things I don't like about this:
- You have to declare a local variable
- You have to clutter the code with concatenation
- You cannot split your code into subroutines unless you pass around your local variable holding the final result
- You have to rewrite every piece of existing code (if you want to use the new region type)
Instead, I want to be able to (continue to) write code like this:

Notice the use of "apex_htp" in the above code; this is a package that does not (yet) exist, but read on!
Or, to give a more complex and real-world example which uses several subprocedures that all write out to the global buffer:

What I think the APEX team should have done
When the APEX team decided that they needed a new region type with a different architecture, instead of just throwing the existing region type into the murky "legacy" territory, they should have made the transition as smooth as possible, by offering a drop-in replacement to the existing HTP package.
I immediately suggested this when I saw the latest APEX version, and as I said on Twitter I think it's a strange decision to hide away the existing method as "legacy" when you are replacing it with a worse dev experience that is not yet fully baked.
To fix this, I've submitted an idea to the APEX Ideas app, to suggest that the APEX team include a new package in the next APEX version that can be used as a drop-in replacement for the HTP package. Using this package with existing code should be as easy as replacing "htp.p" with "apex_htp.p" and adding a single RETURN statement at the end of the region process code.
The spec for such a package could look like the below image. I've already made a working prototype for myself, calling it "xtp", and with a (temporary) synonym I can also call it using "apex_htp", but the point of this blog post (and the submitted idea) is to get this included in APEX itself, where it should have been from day 1 of APEX 22.2. Go and vote today for this idea if you are using PL/SQL Dynamic Content regions!

For those interested in the (just a quick prototype) package body, here it is on GitHub.












































{kind=link}